A job aggregation platform was developed for assisting people of BIPOC ethnicities to search for jobs in different cities of Canada. The platform used Supabase as database and storage and EC2 as compute service. The project was developed in Next.js and uses Open AI API in order to parse and categorize job posts from different company’s career pages. The career page jobs are imported into the platform only on the target company’s request.
API Design Patterns
The application follows a hybrid API architecture combining RESTful principles with Next.js API routes and a third-party BaaS (Backend-as-a-Service) integration.
Pattern Implementation:
- Next.js API Routes: The application uses file-based routing under
/pages/api/for custom business logic, including payment processing (/api/payment/*), candidate operations (/api/candidate/*), and employer features (/api/employer/*). - Resource-Oriented Endpoints: Each API route follows REST conventions with clear resource naming (e.g.,
/api/candidate/applications,/api/employer/jobs,/api/payment/checkout). - Supabase Auto-Generated API: For standard CRUD operations, the app leverages Supabase’s automatically generated RESTful API endpoints derived from PostgreSQL table schemas. This eliminates boilerplate code for basic database operations.
- Service Layer Pattern: Client-side services (
userService,jobService,companyService) encapsulate API calls, providing a clean abstraction layer between UI components and data fetching logic. - Hybrid Request Flow: Simple operations query Supabase directly from the client using the JavaScript SDK, while complex workflows requiring server-side validation or third-party integrations route through Next.js API handlers.
This design reduces development overhead for standard operations while maintaining flexibility for custom business logic.
Authentication Strategy (JWT, RBAC)
The authentication system implements JWT-based stateless authentication with role-based access control managed through Supabase Auth.
JWT Implementation:
- Token Management: Supabase Auth handles JWT generation, refresh, and validation. Access tokens are stored client-side and included in API requests via custom headers (
tokenheader). - Token Validation: API routes extract the JWT from request headers and validate using
Supabase.auth.getUser(token)before processing requests. Invalid or expired tokens trigger immediate rejection with 400 status codes. - Session Handling: The client maintains session state in Redux, storing both the Supabase user object and associated profile data. Session persistence leverages browser storage via Supabase’s built-in session management.
Role-Based Access Control:
- User Roles: The system distinguishes between three primary roles: job seekers (candidates), employers/recruiters, and administrators. Role determination happens through the
is_recruiterflag in user profiles. - Profile-Based Authorization: User capabilities are tied to profile metadata stored in the
profiletable, including credits for job postings, subscription status, and role flags. - Row-Level Security (RLS): Supabase’s RLS policies enforce database-level access control, ensuring users can only access their own data. For example, candidates can only view their applications, and employers can only manage jobs they’ve created.
- API-Level Guards: Custom API routes perform explicit authorization checks by validating both token authenticity and user role before executing operations. The
SupabaseAdminclient bypasses RLS when privileged operations are required.
This multi-layered approach ensures secure, scalable authentication with minimal custom token management code.
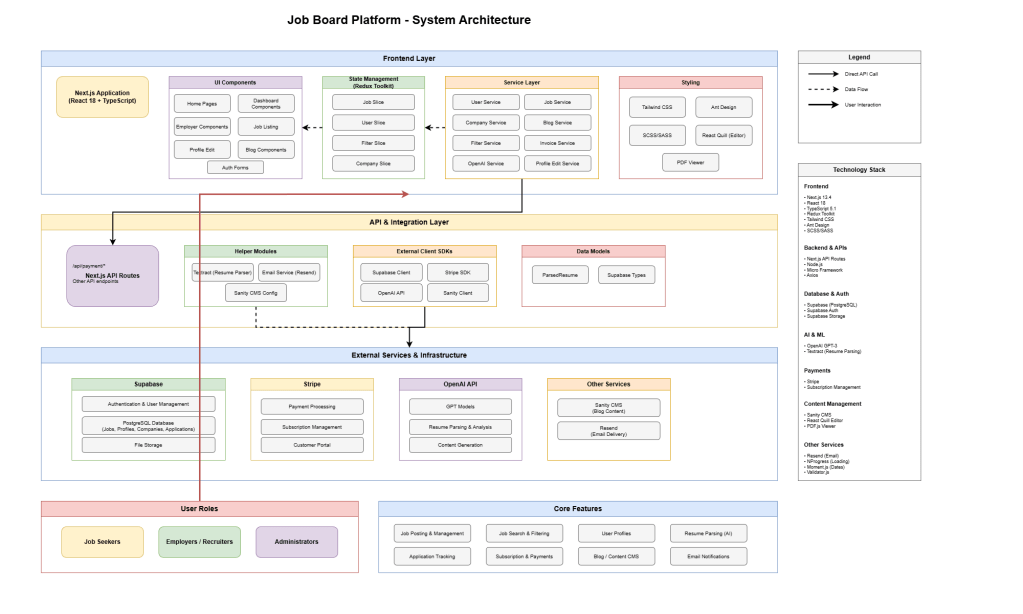
Data Modeling Decisions
The database schema follows a normalized relational model optimized for a job marketplace platform.
Core Entity Design:
- Users & Profiles: Separation between authentication (
auth.usersmanaged by Supabase) and business profiles (profiletable) allows flexible user metadata without coupling to auth logic. Profiles store role flags, credits, parsed resume data, and subscription information. - Jobs & Relationships: The
jobstable uses foreign keys to referencecompany,job_category,job_type,job_location, andyears_experiencetables, enabling structured filtering and consistent metadata across listings. - Applications Tracking: The
applicationstable links job seekers to jobs with additional context (resume, cover letter, status), creating a many-to-many relationship between profiles and jobs with application-specific metadata. - Payments & Credits: A dedicated
paymentstable stores Stripe transaction data, while profile credits enable a credit-based job posting system. This decouples payment processing from job visibility logic.
Type Safety:
- TypeScript types are auto-generated from the PostgreSQL schema using Supabase CLI (
npm run datatypes), ensuring type safety across the stack and preventing schema drift.
Design Rationale:
- Referential Integrity: Foreign key constraints maintain data consistency, preventing orphaned records.
- Denormalization Where Needed: The
parsed_resumeJSON field in profiles stores unstructured AI-parsed data, balancing flexibility with structured access. - Audit Trail:
created_attimestamps across tables enable chronological tracking and analytics.
Caching Strategies
The application employs a selective caching strategy with client-side state management and CDN-based static asset delivery.
Implementation Details:
- Redux State Caching: Frequently accessed data (user profiles, job listings, filter state) is cached in Redux store, reducing redundant API calls during user sessions. State persists across component re-renders.
- Sanity CDN Caching: Blog content served through Sanity CMS leverages their edge CDN (
useCdn: true), providing fast content delivery with automatic invalidation on content updates. - Supabase Storage Caching: File uploads (resumes, profile images, company logos) use Supabase Storage with
cacheControl: '3600'headers, enabling 1-hour browser caching for static assets. - No-Cache for Dynamic Data: Blog service explicitly disables caching for server-side rendering (
cache: 'no-store') to ensure fresh content on each request, critical for SEO-optimized blog pages.
Architectural Choices:
- No Redis/External Cache: Given the moderate scale and Supabase’s built-in connection pooling, the application avoids introducing Redis complexity. Database queries leverage PostgreSQL’s query caching and Supabase’s edge network.
- Client-Side First: The Next.js client-side navigation maintains cached data in memory, minimizing server round-trips for browsing experiences.
Improvement Opportunities: High-traffic deployments could introduce Redis for session storage or API response caching, but current architecture prioritizes simplicity over premature optimization.
Background Jobs / Queues
The application uses webhook-driven asynchronous processing rather than traditional job queues, leveraging third-party service callbacks for long-running tasks.
Webhook-Based Architecture:
- Stripe Webhooks: Payment processing operates asynchronously via Stripe webhooks (
/api/payment/webhook). When checkout completes, Stripe sends acheckout.session.completedevent, triggering job activation, credit updates, and notification emails. - Event-Driven Updates: The webhook handler updates database records atomically (job visibility, payment status, user credits) and triggers downstream actions (email notifications) without blocking the user’s checkout experience.
AI Processing:
- Resume Parsing: OpenAI and Textract integration for resume parsing executes synchronously during upload (
/api/resume), as users expect immediate feedback. Processing times are typically under 5 seconds, making async queuing unnecessary.
Email Delivery:
- Resend Integration: Transactional emails are sent synchronously within API routes but don’t block user responses. The Resend API has sub-second response times, eliminating the need for queuing.
Limitations & Scalability:
- No Dedicated Queue System: The application lacks a traditional job queue (e.g., BullMQ, SQS). For high-volume scenarios requiring retry logic, scheduled tasks, or complex workflows, integrating a queue system would be necessary.
- Process Manager Dependency: Background processes rely on the Next.js server remaining responsive. PM2 or systemd ensures the application restarts on failures, but long-running tasks could benefit from decoupled workers.
Design Rationale: For the current scale, webhook-driven patterns reduce infrastructure complexity while maintaining reliability through Stripe’s retry mechanisms and database transaction atomicity.
Rate Limiting
The application currently implements minimal explicit rate limiting, relying on external service protections and natural request throttling.
Current Approach:
- Supabase Rate Limits: Supabase enforces connection pooling and request quotas at the platform level, preventing database overload. Free tier limits automatically throttle excessive queries.
- Stripe Rate Limiting: Stripe’s API includes built-in rate limits (100 requests/second in live mode), returning 429 status codes when exceeded. The application doesn’t implement retry logic but gracefully handles errors.
- AWS Security Groups: EC2 security groups provide network-level DDoS protection, filtering malicious traffic before reaching the application.
Missing Protections:
- No API Route Throttling: Next.js API routes lack per-user or per-IP rate limiting. A malicious actor could potentially spam resume parsing endpoints (OpenAI calls) or trigger excessive database queries.
- No Client-Side Throttling: UI components don’t implement request debouncing, though antd’s form validation and Redux state management naturally limit rapid submissions.
Recommended Enhancements:
For production scale, consider:
- API Gateway Integration: AWS API Gateway with request throttling (e.g., 100 requests/minute per IP).
- Middleware Rate Limiting: Express-rate-limit or similar middleware in Next.js API routes.
- Redis-Based Tracking: Distributed rate limit counters for multi-instance deployments.
- Supabase RLS: Leveraging RLS policies to prevent users from querying excessive data.
Trade-offs: Current approach minimizes complexity and cost for moderate traffic, but high-growth scenarios require dedicated rate limiting infrastructure.
Error Handling Approach
The application employs a layered error handling strategy with consistent user feedback and debugging capabilities.
Frontend Error Handling:
- Try-Catch Blocks: Service layer functions wrap Supabase queries in try-catch blocks, logging errors to console for debugging while displaying user-friendly messages via antd’s
message.error()andnotification.error()components. - Graceful Degradation: Failed data fetches return
nullor empty arrays, allowing UI components to render default states rather than crashing. Components check for null data before rendering. - User Feedback: Error messages are contextual (“You have already applied for this job” for duplicate applications) rather than exposing technical details like database constraint violations.
Backend Error Handling:
- API Route Guards: All API routes follow a consistent pattern:
- Validate request method
- Extract and verify JWT token
- Execute business logic in try-catch
- Return structured JSON responses (
{ status: boolean, message: string })
- HTTP Status Codes: Proper status codes signal error types (400 for client errors, 405 for method not allowed). However, some error cases inconsistently return 400 instead of 401 (unauthorized) or 500 (server errors).
- Webhook Error Recovery: Stripe webhook handler uses specific error messages to identify failure points, enabling Stripe’s automatic retry mechanism. Failed events are logged but don’t crash the endpoint.
Logging & Monitoring:
- Console Logging: Errors are logged to stdout with
console.log(error.message), enabling CloudWatch log aggregation on EC2 deployments. - No Structured Logging: The application lacks a structured logging framework (e.g., Winston, Pino), making production debugging more difficult.
Improvement Opportunities:
- Error Tracking Service: Integrate Sentry or similar for real-time error monitoring and stack traces.
- Structured Logging: Adopt JSON-formatted logs with request IDs for traceability.
- Centralized Error Handling: Create middleware to standardize error responses across API routes.
- Retry Logic: Implement exponential backoff for transient failures (network timeouts, rate limits).
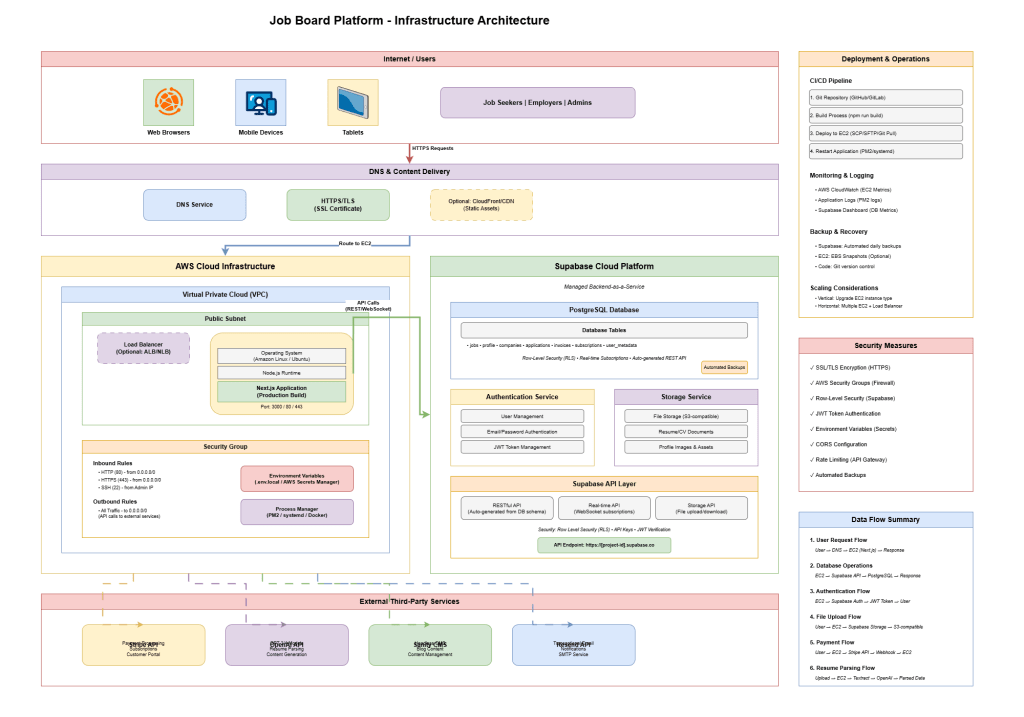
CI/CD Flow (High Level)
The application follows a manual deployment workflow with potential for GitHub Actions or similar CI/CD automation.
Current Deployment Process:
- Development: Developers work locally with
npm run dev, connecting to production Supabase instances. - Code Commit: Changes are pushed to a Git repository (GitHub/GitLab). The repository structure includes environment files (.env.local) that are excluded from version control.
- Build Process:
- Run
npm run buildto create production-optimized Next.js static and server bundles - Type generation via
npm run datatypesensures TypeScript types match database schema
- Deployment to EC2:
- Transfer build artifacts to EC2 instance via SCP, SFTP, or
git pullon the server - Environment variables are manually configured on EC2 (via .env.local or AWS Secrets Manager)
- Application Restart:
- Process manager (PM2 recommended) restarts the Next.js application:
pm2 restart apporpm2 start npm --name "app" -- start - systemd service restart is an alternative for production environments
Automated CI/CD Enhancements:
A typical automated pipeline would include:
- CI Pipeline (GitHub Actions/GitLab CI):
- Trigger on push to main branch
- Install dependencies (
npm install) - Run linter (
npm run lint) - Run type checks (
tsc --noEmit) - Build production bundle (
npm run build) - Run tests (if implemented)
- CD Pipeline:
- Package build artifacts
- Deploy to EC2 via SSH or AWS CodeDeploy
- Run database migrations (if schema changes)
- Restart application with zero-downtime (e.g., PM2 cluster mode)
- Health check verification
Environment Management:
- Single Environment: The application appears to use a single production Supabase instance. Best practices would include separate staging/production environments with different API keys and database instances.
Monitoring Post-Deployment:
- CloudWatch metrics track EC2 health (CPU, memory, disk)
- Application logs accessible via PM2 logs or CloudWatch Logs agent
- Supabase dashboard provides database metrics and query performance
Security Considerations:
- SSH keys or IAM roles should control EC2 access
- Secrets (API keys, database credentials) should use AWS Secrets Manager or environment variables, never hardcoded
This manual deployment approach is sufficient for small teams but would benefit from automation for faster iteration, reduced human error, and improved rollback capabilities.

Leave a comment